Hadoop——完全分布式搭建
1、修改主机名
配置/etc/hosts文件,四台服务器均需要配置。
[root@nna /root]# vi /etc/hosts
192.168.206.200 nna
192.168.206.202 dn1
192.168.206.203 dn2
192.168.206.204 dn3
2、配置ssh免密通信
2.1、在nna主机上生成秘钥对
[root@nna /root]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:aU46oAu1Ut8pF6yGU734IC4tVI7j5jVMC9CwPLjIPBE root@nna
The key's randomart image is:
+---[RSA 2048]----+
|.E |
|o+. |
|++. |
|=.o. o . |
|o=*.o + S |
| *=B.= O |
|=.B=B B . |
|o*o=.= . |
|o+o . |
+----[SHA256]-----+
[root@nna /root]# cd .ssh/
[root@nna /root/.ssh]# ll
total 8
-rw-------. 1 root root 1675 Aug 25 00:42 id_rsa
-rw-r--r--. 1 root root 390 Aug 25 00:42 id_rsa.pub
2.2、将公钥文件id_rsa.pub远程复制到各个主机上(包括自己)
放置在/root/.ssh/authorized_keys中
[root@nna /root/.ssh]# scp id_rsa.pub root@nna:/root/.ssh/authorized_keys
[root@nna /root/.ssh]# scp id_rsa.pub root@dn1:/root/.ssh/authorized_keys
[root@nna /root/.ssh]# scp id_rsa.pub root@dn2:/root/.ssh/authorized_keys
[root@nna /root/.ssh]# scp id_rsa.pub root@dn3:/root/.ssh/authorized_keys
3、配置完全分布式
3.1、进入$HADOOP_HOME/etc/hadoop目录
[root@nna /opt]# cd $HADOOP_HOME/etc/hadoop
3.2、编辑core-site.xml文件
这里需要配置对应的主机名称
[root@nna /usr/local/hadoop/etc/hadoop]# vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://nna</value>
</property>
</configuration>
3.3、编辑hdfs-site.xml文件
数据节点变成了3台这里的value值需要改成3
[root@nna /usr/local/hadoop/etc/hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
3.4、编辑mapred-site.xml文件
这里和伪分布式一样不需要修改
[root@nna /usr/local/hadoop/etc/hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.5、编辑yarn-site.xml文件
[root@nna /usr/local/hadoop/etc/hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 配置主机名 -->
<value>nna</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.6、配置slave文件
添加数据节点的主机名称
[root@nna /usr/local/hadoop/etc/hadoop]# vi slaves
dn1
dn2
dn3
3.7、修改hadoop环境配置文件,手动指定JAVA_HOME环境变量
[root@nna /usr/local/hadoop/etc/hadoop]# vi hadoop-env.sh
...
export JAVA_HOME=/usr/local/java
...
4、分发配置
4.1、将$HADOOP_HOME/etc目录下的hadoop文件夹分发至数据节点
[root@dn1 /usr/local/hadoop/etc]# scp -r hadoop root@dn1:/usr/local/hadoop/etc/
[root@dn1 /usr/local/hadoop/etc]# scp -r hadoop root@dn2:/usr/local/hadoop/etc/
[root@dn1 /usr/local/hadoop/etc]# scp -r hadoop root@dn3:/usr/local/hadoop/etc/
4.2、删除临时目录文件
[root@nna /root]# rm -rf /tmp/hadoop-root
[root@nna /root]# ssh dn1 rm -rf /tmp/hadoop-root
[root@nna /root]# ssh dn2 rm -rf /tmp/hadoop-root
[root@nna /root]# ssh dn3 rm -rf /tmp/hadoop-root
4.3、删除hadoop日志
[root@nna /root]# rm -rf /usr/local/hadoop/logs/*
[root@nna /root]# ssh dn1 rm -rf /usr/local/hadoop/logs/*
[root@nna /root]# ssh dn2 rm -rf /usr/local/hadoop/logs/*
[root@nna /root]# ssh dn3 rm -rf /usr/local/hadoop/logs/*
5、完全分布式测试
5.1、格式化文件系统
[root@nna /root]# hadoop namenode -format
5.2、启动hadoop的所有进程
可以看到分别启动了目录节点和数据节点
[root@nna /root]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [nna]
nna: starting namenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-namenode-nna.out
dn2: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-dn2.out
dn3: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-dn3.out
dn1: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-dn1.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-nna.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-resourcemanager-nna.out
dn1: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-dn1.out
dn2: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-dn2.out
dn3: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-dn3.out
5.3、通过jps查看启动了的进程
目录节点进程
[root@nna /root]# jps
25664 NameNode
25856 SecondaryNameNode
26274 Jps
26012 ResourceManager
数据节点进程
[root@dn1 /root]# jps
13793 NodeManager
13954 Jps
6426 QuorumPeerMain
13676 DataNode
5.3、通过浏览器查看hadoop的文件系统
是能够看到3个数据节点信息的
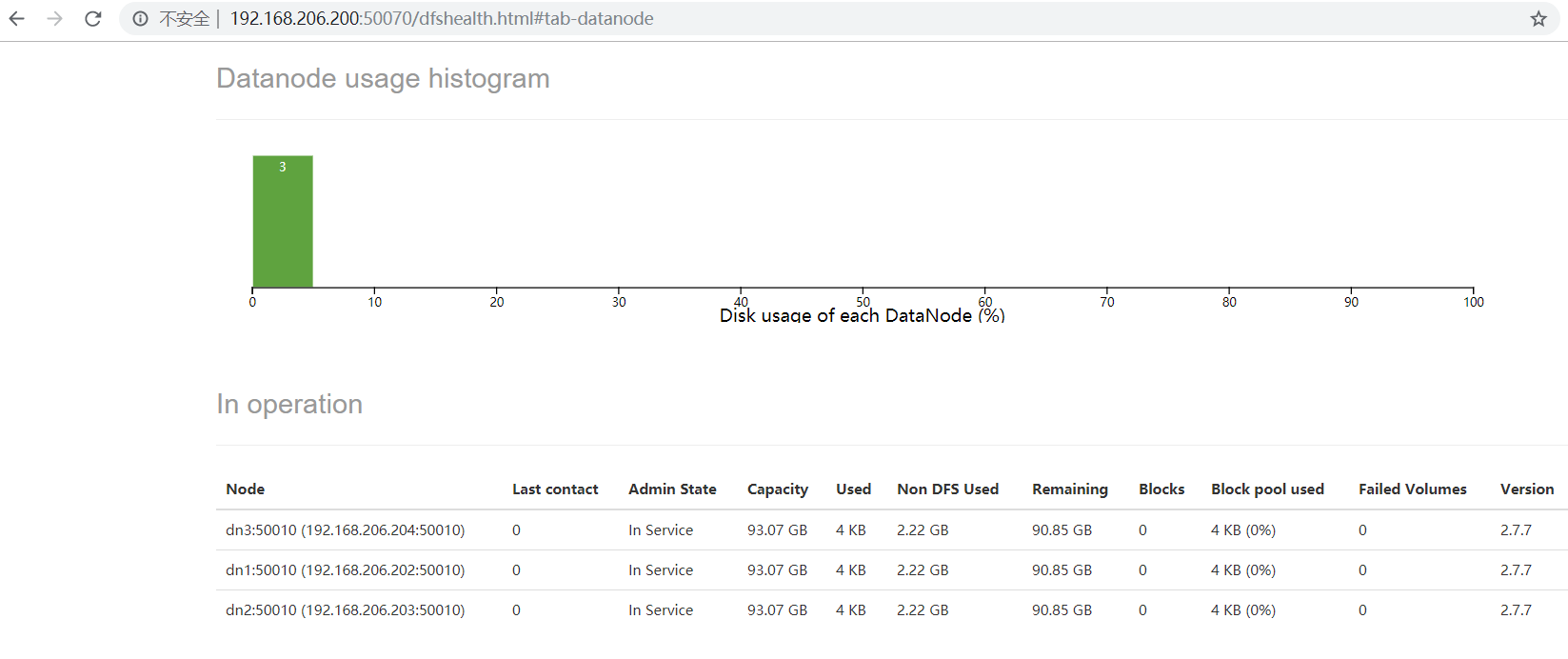
5.4、停止hadoop所有进程
[root@nna /root]# stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [nna]
nna: stopping namenode
dn2: stopping datanode
dn3: stopping datanode
dn1: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
dn3: stopping nodemanager
dn2: stopping nodemanager
dn1: stopping nodemanager
no proxyserver to stop