[root@nna /opt]# tar zxvf jdk-8u65-linux-x64.tar.gz
[root@nna /opt]# ln -s /opt/jdk1.8.0_65/ /usr/local/java
[root@nna /opt]# vi /etc/profile
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
[root@nna /opt]# source /etc/profile
[root@nna /opt]# tar zxvf hadoop-2.7.7.tar.gz
[root@nna /opt]# ln -s /opt/hadoop-2.7.7 /usr/local/hadoop
[root@nna /opt]# vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
[root@nna /opt]# source /etc/profile
[root@nna /opt]# cd $HADOOP_HOME/etc/hadoop
[root@nna /usr/local/hadoop/etc/hadoop]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost/</value>
</property>
</configuration>
[root@nna /usr/local/hadoop/etc/hadoop]# vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
[root@nna /usr/local/hadoop/etc/hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@nna /usr/local/hadoop/etc/hadoop]# vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@nna /usr/local/hadoop/etc/hadoop]# vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<!-- 配置主机名 -->
<value>nna</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
[root@nna /root]# ps -ef | grep sshd
root 4993 1 0 Aug23 ? 00:00:00 /usr/sbin/sshd -D
root 5509 4993 0 Aug23 ? 00:00:13 sshd: root@pts/0
root 7269 4993 0 Aug24 ? 00:00:00 sshd: root@pts/1
root 14509 7274 0 00:39 pts/1 00:00:00 grep --color=auto sshd
[root@nna /root]# ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Created directory '/root/.ssh'.
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:aU46oAu1Ut8pF6yGU734IC4tVI7j5jVMC9CwPLjIPBE root@nna
The key's randomart image is:
+---[RSA 2048]----+
|.E |
|o+. |
|++. |
|=.o. o . |
|o=*.o + S |
| *=B.= O |
|=.B=B B . |
|o*o=.= . |
|o+o . |
+----[SHA256]-----+
[root@nna /root]# cd .ssh/
[root@nna /root/.ssh]# ll
total 8
-rw-------. 1 root root 1675 Aug 25 00:42 id_rsa
-rw-r--r--. 1 root root 390 Aug 25 00:42 id_rsa.pub
[root@nna /root/.ssh]# cat id_rsa.pub >> authorized_keys
[root@nna /root/.ssh]# chmod 644 authorized_keys
[root@nna /root/.ssh]# ssh nna
Last login: Sun Aug 25 00:44:55 2019 from nna
[root@nna /root]#
[root@nna /root]# cd $HADOOP_HOME/etc/hadoop/
[root@nna /usr/local/hadoop/etc/hadoop]# vi hadoop-env.sh
...
export JAVA_HOME=/usr/local/java
...
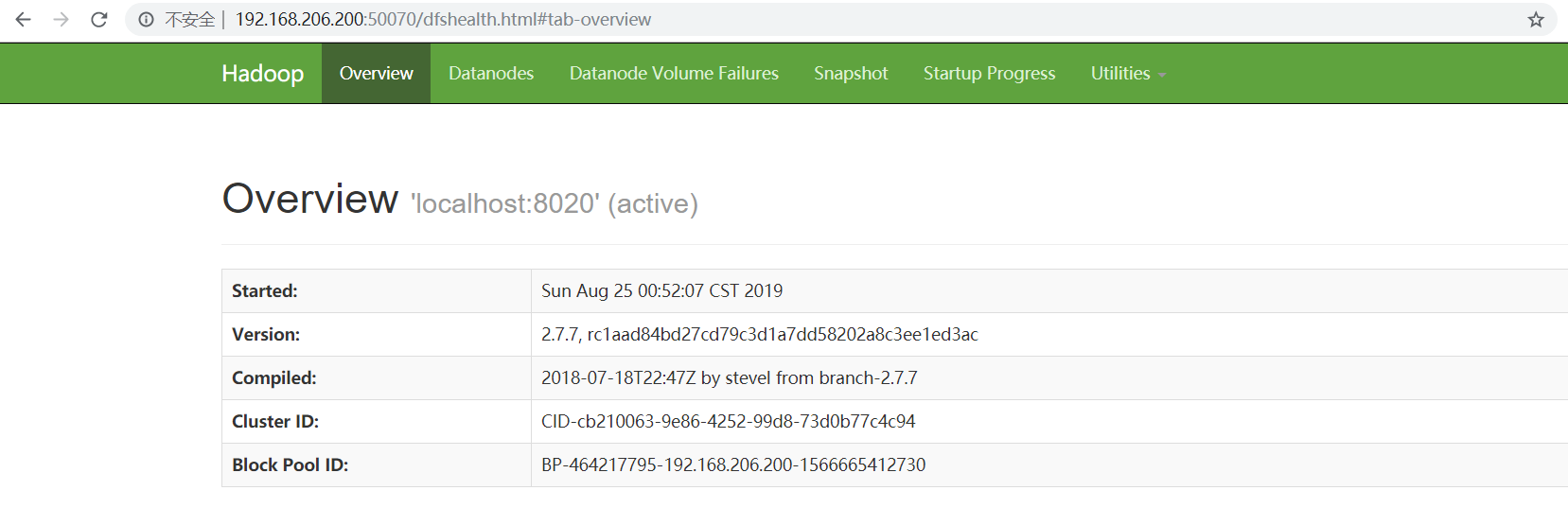
[root@nna /root]# hadoop namenode -format
[root@nna /root]# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-namenode-nna.out
localhost: starting datanode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-datanode-nna.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop-2.7.7/logs/hadoop-root-secondarynamenode-nna.out
starting yarn daemons
starting resourcemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-resourcemanager-nna.out
localhost: starting nodemanager, logging to /opt/hadoop-2.7.7/logs/yarn-root-nodemanager-nna.out
[root@nna /root]# jps
16226 NameNode
16899 NodeManager
16516 SecondaryNameNode
16676 ResourceManager
17095 Jps
[root@nna /root]# hdfs dfs -ls /
[root@nna /root]# hdfs dfs -mkdir -p /caosw/test
[root@nna /root]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2019-08-25 00:55 /caosw
[root@nna /root]# stop-all.sh
This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: no datanode to stop
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
stopping yarn daemons
stopping resourcemanager
localhost: stopping nodemanager
no proxyserver to stop